In the section on phonotactic acceptability, we saw that speakers’ judgments about whether a string of phones could be a word of English are gradient—some nonwords are judged as very wordlike, others as very un-wordlike, and many fall in between. The same is true for morphological structure. Some novel combinations of morphemes sound perfectly natural (re-doable, un-testable), others sound awkward but comprehensible (de-publicize, over-mentorship), and others sound clearly wrong (ness-happy, un-tion).
Oseki and Marantz (2020) collected acceptability judgments for morphologically complex nonwords in English. Participants rated each nonword on a scale, and the resulting judgments—like the phonotactic judgments from Daland et al. (2011)—show clear gradience.
The acceptability data
Let’s load and explore the judgment data.
import numpy as npimport pandas as pdimport matplotlib.pyplot as plttrials = pd.read_csv('data/trials.csv')print(f"Total judgments: {len(trials)}")print(f"Unique words: {trials.word.nunique()}")print(f"Unique subjects: {trials.subject.nunique()}")trials.head()
Total judgments: 16600
Unique words: 600
Unique subjects: 166
subject
word
order
judgment
judgment_z
0
subject1
archetypally
1
5.0
-1.215781
1
subject1
depublicize
2
6.0
0.108069
2
subject1
decoratorship
3
6.0
0.108069
3
subject1
surveyorship
4
6.0
0.108069
4
subject1
preprohibition
5
7.0
1.431920
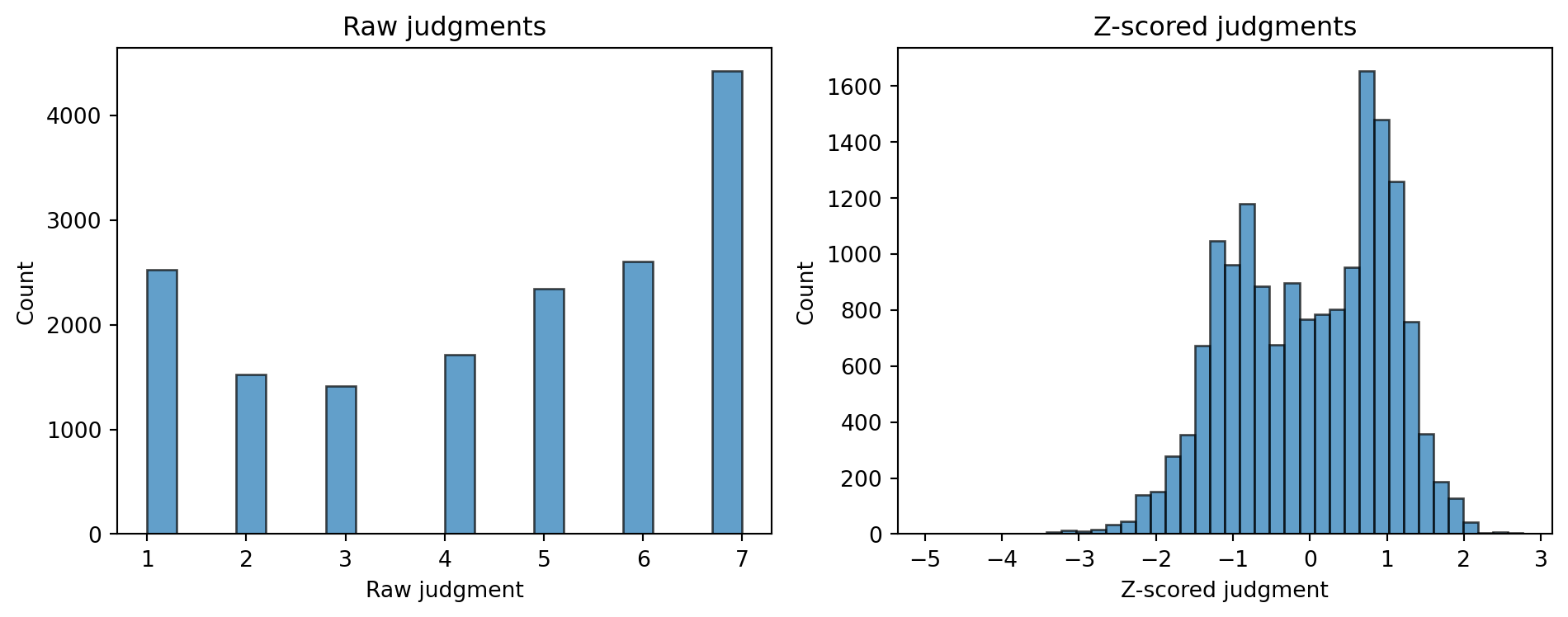
The judgment column contains raw ratings and judgment_z contains z-scored ratings, normalized per participant to account for individual differences in scale use.
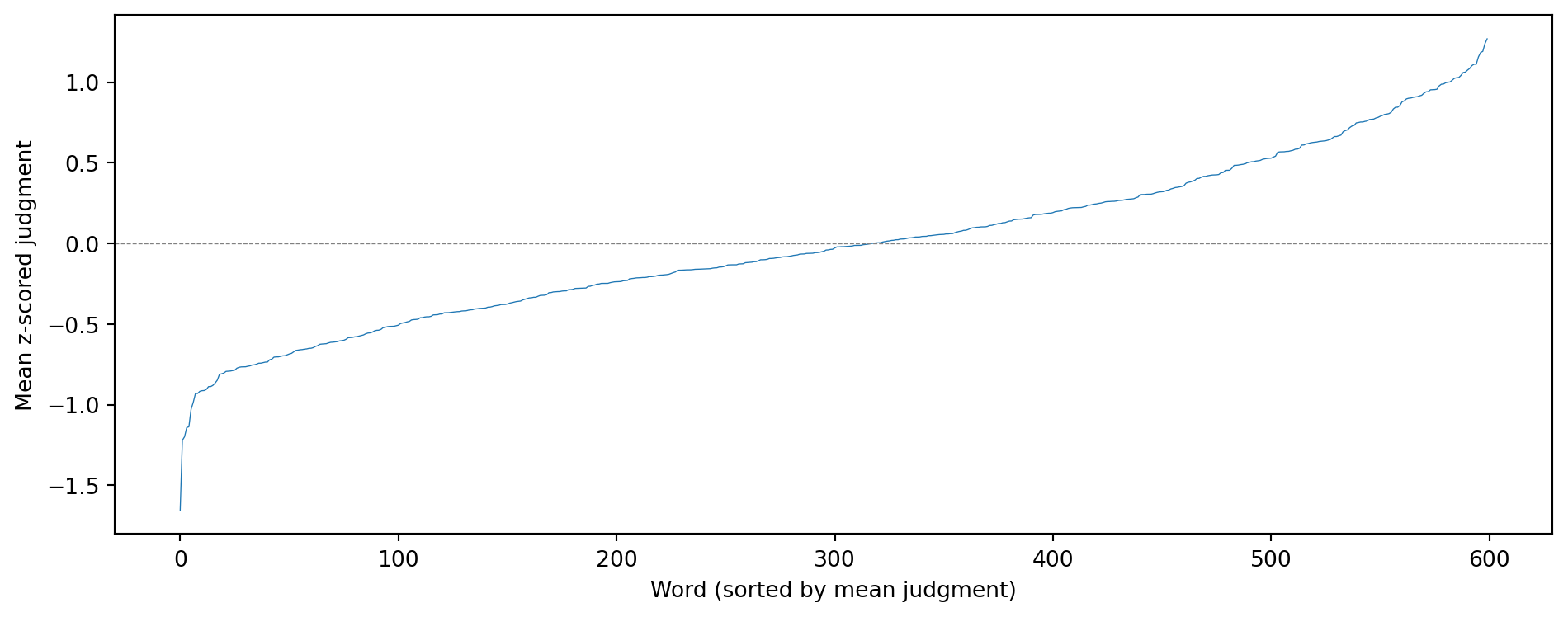
Most acceptable:
word
murkiness 1.156299
intercultural 1.183585
equalizer 1.190713
adjustability 1.239054
digitally 1.268842
Name: judgment_z, dtype: float64
Least acceptable:
word
refrigeratorship -1.656313
incisorship -1.221015
liveriness -1.198991
incineratorship -1.142210
interideal -1.137114
Name: judgment_z, dtype: float64
What kind of model do we need?
The gradience in these judgments raises the same question we encountered for phonotactics: can we build a model that predicts it? Before doing so, it’s worth pausing to consider what class of formal machinery we might need.
As I discussed in the module overview, Chandlee (2014) showed that most morphological transformations are subsequential functions—a proper subclass of the regular relations. Prefixation, suffixation, and local infixation can all be computed by finite state transducers with very restricted structure. This is the morphological analogue of the finding that phonotactic constraints are subregular: the computational machinery that morphology uses is, for the most part, quite simple.
But the operative phrase is “for the most part.” Total reduplication requires unbounded copying, which exceeds the power of any finite state device. And morphological structure—the hierarchical constituency that determines whether unlockable means “not able to be locked” or “able to be unlocked”—is not a property of the transformation itself but of the grammar that licenses it. Modeling this constituency requires context-free grammars, which is why we developed them in the preceding sections.
In the pages that follow, we’ll build up the tools needed to train such grammars on real data and evaluate how well they predict the kind of gradient acceptability judgments we’ve just seen. The first step is to get our hands on a morphological database that provides gold-standard parses. Then we’ll explore several approaches to morphological segmentation—the problem of finding morpheme boundaries—before turning to probabilistic context-free grammars that assign scores to morphological structures.
References
Chandlee, Jane. 2014. “Strictly Local Phonological Processes.” PhD thesis, University of Delaware.
Daland, Robert, Bruce Hayes, James White, Marc Garellek, Andrea Davis, and Ingrid Norrmann. 2011. “Explaining Sonority Projection Effects.”Phonology 28 (2): 197–234.
Oseki, Yohei, and Alec Marantz. 2020. “Modeling Morphological Well-Formedness.”Proceedings of the Society for Computation in Linguistics 3: 1–10.
Source Code
---title: Morphological well-formednessbibliography: ../references.bibjupyter: python3---In the [section on phonotactic acceptability](../uncertainty-about-languages/ngram-models.qmd), we saw that speakers' judgments about whether a string of phones could be a word of English are gradient—some nonwords are judged as very wordlike, others as very un-wordlike, and many fall in between. The same is true for morphological structure. Some novel combinations of morphemes sound perfectly natural (*re-doable*, *un-testable*), others sound awkward but comprehensible (*de-publicize*, *over-mentorship*), and others sound clearly wrong (*ness-happy*, *un-tion*).@oseki2020modeling collected acceptability judgments for morphologically complex nonwords in English. Participants rated each nonword on a scale, and the resulting judgments—like the phonotactic judgments from @daland_explaining_2011—show clear gradience.## The acceptability dataLet's load and explore the judgment data.```{python}import numpy as npimport pandas as pdimport matplotlib.pyplot as plttrials = pd.read_csv('data/trials.csv')print(f"Total judgments: {len(trials)}")print(f"Unique words: {trials.word.nunique()}")print(f"Unique subjects: {trials.subject.nunique()}")trials.head()```The `judgment` column contains raw ratings and `judgment_z` contains z-scored ratings, normalized per participant to account for individual differences in scale use.```{python}#| code-fold: true#| code-summary: Distribution of acceptability judgmentsfig, axes = plt.subplots(1, 2, figsize=(10, 4))axes[0].hist(trials.judgment, bins=20, edgecolor='black', alpha=0.7)axes[0].set_xlabel('Raw judgment')axes[0].set_ylabel('Count')axes[0].set_title('Raw judgments')axes[1].hist(trials.judgment_z, bins=40, edgecolor='black', alpha=0.7)axes[1].set_xlabel('Z-scored judgment')axes[1].set_ylabel('Count')axes[1].set_title('Z-scored judgments')fig.tight_layout()plt.show()```We can also look at the average z-scored judgment for each word:```{python}#| code-fold: true#| code-summary: Per-word average acceptabilityword_means = trials.groupby('word').judgment_z.mean().sort_values()fig, ax = plt.subplots(1, 1, figsize=(10, 4))ax.plot(range(len(word_means)), word_means.values, linewidth=0.5)ax.set_xlabel('Word (sorted by mean judgment)')ax.set_ylabel('Mean z-scored judgment')ax.axhline(0, color='gray', linestyle='--', linewidth=0.5)fig.tight_layout()plt.show()print("Most acceptable:")print(word_means.tail(5))print("\nLeast acceptable:")print(word_means.head(5))```## What kind of model do we need?The gradience in these judgments raises the same question we encountered for phonotactics: can we build a model that predicts it? Before doing so, it's worth pausing to consider what class of formal machinery we might need.As I discussed in the [module overview](index.qmd), @chandlee2014strictly showed that most morphological transformations are *subsequential functions*—a proper subclass of the regular relations. Prefixation, suffixation, and local infixation can all be computed by finite state transducers with very restricted structure. This is the morphological analogue of the finding that phonotactic constraints are subregular: the computational machinery that morphology uses is, for the most part, quite simple.But the operative phrase is "for the most part." Total reduplication requires unbounded copying, which exceeds the power of any finite state device. And morphological *structure*—the hierarchical constituency that determines whether *unlockable* means "not able to be locked" or "able to be unlocked"—is not a property of the transformation itself but of the *grammar* that licenses it. Modeling this constituency requires context-free grammars, which is why we developed them in the preceding sections.In the pages that follow, we'll build up the tools needed to train such grammars on real data and evaluate how well they predict the kind of gradient acceptability judgments we've just seen. The first step is to get our hands on a morphological database that provides gold-standard parses. Then we'll explore several approaches to morphological segmentation—the problem of finding morpheme boundaries—before turning to probabilistic context-free grammars that assign scores to morphological structures.