import osfrom pandas import DataFrame, read_csv, concatdef load_data(fname: str, remove_fillers: bool=False) -> DataFrame:"""Load Sprouse et al.'s (2016) data Parameters ---------- fname The filename of the data remove_fillers Whether to remove the fillers Returns ------- data The data """# read the raw data skipping comment rows at the beginning data = read_csv(fname, skiprows=5)# remove NaN judgments data = data.query("~judgment.isnull()")# fill NaNsfor col in ["dependency", "structure", "distance", "island"]: data.loc[:,col] = data[col].fillna("filler")# remove fillersif remove_fillers: data = data.query("dependency != 'filler'")return datadata_dir ="./data/SCGC.data/"data_exp1_test = load_data( os.path.join(data_dir, "Experiment 1 results - English.csv"), remove_fillers=True)data_exp3_test = load_data( os.path.join(data_dir, "Experiment 3 results - English D-linking.csv"), remove_fillers=True)data_exp3_test["dependency"] = data_exp3_test.dependency.map({"WH": "DlinkedWH", "RC": "DlinkedRC", "filler": "filler"})data_exp1_test["exp"] =1data_exp3_test["exp"] =3data_test = concat([data_exp1_test, data_exp3_test])
We will fit our model families using Markov chain Monte Carlo (MCMC) as implemented in STAN. As I mentioned in the last section, you can find a very brief introduction to MCMC in STAN here in the course notes on statistical inference.
To compare our model families, we want to quantitatively measure the fit of those theories’ best analyses to the data (identified by a particular parameterization) and–as a measure of parsimony–weight that fit against how many such best analyses there are. The more constrained the family of theories, the fewer such best analyses it will have and thus the more parsimonious we will consider it. A common way to implement this comparison is using an information criterion.
Most information criteria attempt to estimate (a family of) models’ performance on data it was not fit to (Gelman, Hwang, and Vehtari 2014). They have have two components: a measure of the model’s fit to the data–usually the log-likelihood of the data–and a measure of the complexity of the family of models. Model complexity can be computed from a point estimate (the maximum likelihood estimate) directly in terms of the number of parameters in the model family–as in the Akaike Information Criterion (AIC) or the Bayesian Information Criterion–or in terms of variability in the likelihood conditioning on samples from the posterior–as in the Deviance Information Criterion (DIC) and the Watanabe-Akaike (or Widely Applicable) Information Criterion (WAIC). The rough idea behind using the latter is that–more expressive models will show more variability in the likelihood for a particular observation, since there are more good analyses under the model due to its flexibility. The information criterion is then a combination of the measure of fit and the measure of complexity.
We will use Pareto smoothed importance sampling leave-one-out cross-validation (PSIS-LOO), which is a gold-standard for information criteria (Vehtari, Gelman, and Gabry 2017). This criterion attempts to estimate a model’s performance on responses it was not fit to using importance sampling–a basic version of which we covered here in the course notes on statistical inference.
An initial fit
To get started, let’s fit our intercept-only model using the cmdstanpy interface to STAN. We’ll start by defining how to map (or hash) columns of our data to indices. We’ll use this for hashing subject identifiers here and item identifiers later.
from numpy import ndarrayfrom pandas import Seriesdef hash_series(series: Series, indexation: int=1) ->tuple[ndarray, ndarray]:"""Hash a series to numeric codes Parameters ---------- column The series to hash index The starting index (defaults to 1) """# enforce 0- or 1-indexationif indexation notin [0, 1]:raiseValueError("Must choose either 0- or 1-indexation.")# convert the series to a category category_series = series.astype("category")# get the hash hash_map = category_series.cat.categories.values# map to one-indexed codes hashed_series = (category_series.cat.codes + indexation).valuesreturn hash_map, hashed_series
We then need to define how to construct data for input to our STAN model from the data collected by (Sprouse et al. 2016).
The output of this function must exactly match our data block (and it does).
data {int<lower=0> N_resp; // number of responsesint<lower=0> N_subj; // number of subjectsint<lower=2> N_resp_levels; // number of possible likert scale acceptability judgment responsesint<lower=1,upper=N_subj> subj[N_resp]; // subject who gave response nint<lower=1,upper=N_resp_levels> resp[N_resp]; // likert scale acceptability judgment responses }
Next, we will define a function that constructs the data, compiles the model, and fits it.
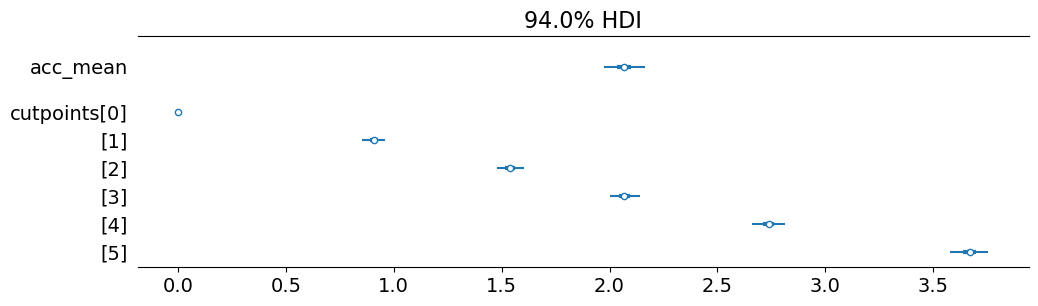
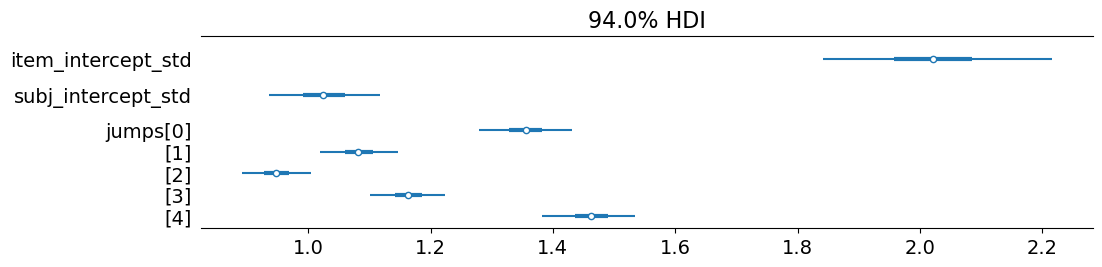
We can peak at the posterior distribution over the intercept term (acc_mean) and the cutpoints. We see that the intercept term falls just about at the cutpoint between the 4 and 5 bins.
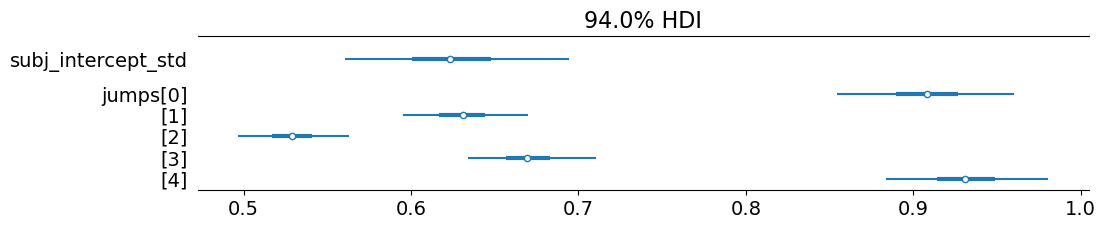
If we look at the jumps, we note that there tends to be a preference for ordinal response levels that are nearer to the edges of the scale–with the bin size for 4 (jumps[2]) almost half the bin size of 2 (jumps[0]) and 6 (jumps[4]). The relative size of subj_intercept_std indicates that subjects can differ in their left- or right-bias by approximately an entire ordinal response level.
To faciliate code reuse, we’ll develop an abstract base class (ABC) that defines our fitting procedure. The main things to focus on here are the IslandEffectsModel.construct_model_data and IslandEffectsModel.fit methods–the lattr of which is modeled on the sklearn API.
import cmdstanpyfrom abc import ABCfrom typing import Optionalfrom dataclasses import dataclassfrom numpy import ndarrayfrom cmdstanpy import CmdStanModel@dataclassclass IslandEffectsData: N_resp: int# number of responses N_subj: int# number of subjects N_resp_levels: int# number of possible likert scale acceptability judgment responses subj: ndarray # subject who gave response n resp: ndarray # likert scale acceptability judgment responsesclass IslandEffectsModel(ABC):"""An abstract base class for island effects models""" stan_file: str data_class = IslandEffectsDatadef__init__(self):self.model = CmdStanModel(stan_file=self.stan_file)def construct_model_data(self, data: DataFrame): subj_hash_map, subj_hashed = hash_series(data.subject)return {"N_resp": data.shape[0],"N_subj": subj_hash_map.shape[0],"N_resp_levels": 7,"subj": subj_hashed,"resp": data.judgment.astype(int).values }def _validate_data(self):self.data_class(**self.model_data)def fit(self, data: DataFrame, save_dir: Optional[str] =None, verbose: bool=False, map_initialization: bool=True, seed: int=50493,**kwargs ) -> InferenceData:if verbose:print("Constructing model data...")self.model_data =self.construct_model_data(data)self._validate_data()if map_initialization:if verbose:print("Fitting model with MAP initialization...") map_estimate =self._compute_map_estimate(seed)if"inits"in kwargs:# inits passed to fit() should override MAP map_estimate.update(kwargs["inits"]) kwargs["inits"] = map_estimateelif verbose:print("Fitting model...")# sample from the posterior starting at the MAPself.raw_model_fit =self.model.sample( data=self.model_data,**kwargs )if save_dir isnotNone:if verbose:print("Saving model...")self.save(save_dir)if verbose:print("Running MCMC diagnostics...")print()print(self.diagnose())returnselfdef _compute_map_estimate(self, seed: int):# compute MAP fitself.map_model_fit =self.model.optimize( data=self.model_data, seed=seed, algorithm="lbfgs", tol_obj=1. )returnself.map_model_fit.stan_variables()@propertydef model_fit(self):return arviz.from_cmdstanpy(self.raw_model_fit)def save(self, save_dir: str="."):self.raw_model_fit.save_csvfiles(save_dir)@classmethoddef from_csv(cls, path: str, **kwargs): model = cls(**kwargs) model.raw_model_fit = cmdstanpy.from_csv(path)def diagnose(self):returnself.raw_model_fit.diagnose()
It is then straightforward to simply specify the STAN model file as a class attribute of some subclass of this ABC.
class InterceptOnlyModel(IslandEffectsModel): stan_file ="models/intercept-only-model/intercept-only-model.stan"
We can similarly specify and fit our item random effects model by (i) specifying the appropriate STAN file; and (ii) adding item information to the model’s data representation.
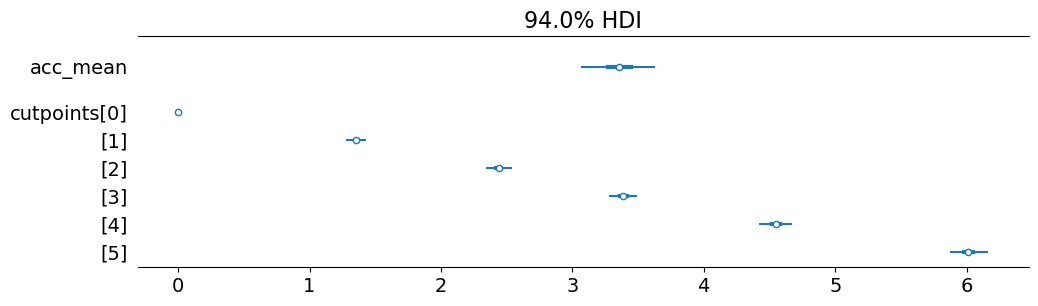
It also yields a similar posterior distribution for subj_intercept_std and jumps. As we would expect, since it is the only way that differences among items can be explained, item_intercept_std is substantially larger than subj_intercept_std.
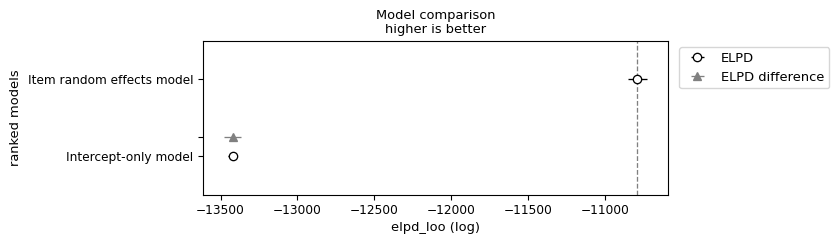
If we compare these two models using PSIS-LOO–measured in terms of expected log-pointwise density (ELPD)–we observe that (unsurprisingly) the item random effects model fits the data substantially better. This can be seen by the fact that its ELPD is substantially higher.
from arviz import comparecompare_dict = {"Intercept-only model": intercept_only_model.model_fit, "Item random effects model": item_random_effects_model.model_fit}model_comparison = compare(compare_dict)
Plotting code
from arviz import plot_compare_ = plot_compare(model_comparison)
If we look at the item random intercept model’s \(p_\text{loo}\), which is the measure of model complexity, we also see that it is substantially higher. But because the fit is so much better, when we combine \(p_\text{loo}\) with the likelihood to derive ELPD\(_\text{loo}\), the model is still preferred.
As we move forward, we will be particularly interested in elpd_diff and dse. elpd_diff tells us how much better the best model family in terms of PSIS-LOO is, and dse tells us the standard error of that difference. One important thing to note is that we can also compute a standard error of ELPD\(_\text{loo}\) itself (se above), but dse is note computable from this quantity, since dse is computed pointwise.2
Mixed effects models
To implement our three vanilla mixed effects models–the no interaction model, minimal interaction model, and maximal interaction model–we will develop an generalization of the ABC that accepts formulae for the fixed effects, by-item effect, and by-subject effects.
@dataclassclass MixedEffectsData(IslandEffectsData): N_fixed: int# number of fixed predictors fixed_predictors: ndarray # predictors (length and dependency type) including intercept N_item: int# number of items N_by_item: int# number of random by-item predictors by_item_predictors: ndarray # by-item predictors (length and dependency type) including intercept N_by_subj: int# number of random by-subject predictors by_subj_predictors: ndarray # by-subject predictors (length and dependency type) including intercept item: ndarray # item corresponding to response n
To implement the clustered mixed effects models, we need to add a way of specifying which interactions we would like to model as discrete. We’ll enforce that, if an item does not instantiate distance=long and island=island, it gets mapped to no_interaction.
@dataclassclass ClusteredMixedEffectsData(MixedEffectsData): N_grammaticality_levels: int# number of grammaticality levels N_interactions: int# number of interactions to model as discrete interactions: ndarray # interactions to model as discrete class ClusteredMixedEffectsModel(MixedEffectsModel): data_class = ClusteredMixedEffectsDatadef__init__(self, n_grammaticality_levels: int, **kwargs):super().__init__(**kwargs)self.n_grammaticality_levels = n_grammaticality_levelsdef construct_model_data(self, data: DataFrame): model_data =super().construct_model_data(data)self.interactions_hash, interactions = hash_series( data[["distance", "structure", "island", "dependency"]].apply(lambda x: x[2] +"_"+ x[3] if x[0] =="long"and x[1] =="island"else"no_interaction", axis=1 ) ) model_data.update({"N_grammaticality_levels": self.n_grammaticality_levels,"N_interactions": self.interactions_hash.shape[0],"interactions": interactions })return model_dataclass ConstrainedClusteredMixedEffectsModel(ClusteredMixedEffectsModel): stan_file ="models/constrained-clustered-interaction-model/constrained-clustered-interaction-model.stan"class UnconstrainedClusteredMixedEffectsModel(ClusteredMixedEffectsModel): stan_file ="models/unconstrained-clustered-interaction-model/unconstrained-clustered-interaction-model.stan"def _compute_map_estimate(self, seed:int): map_estimate =super()._compute_map_estimate(seed)for vname, v in map_estimate.items():if"penalty"in vname andnothasattr(v, "shape"): map_estimate[vname] = array([v])return map_estimate
We will consider models with 2, 3, and 4 levels of grammaticality.
discrete_models = {}continuous_models = {}for g inrange(2, 5):print(f"Fitting discrete model with {g} grammaticality levels...") constrained_models[g] = ConstrainedClusteredMixedEffectsModel( n_grammaticality_levels=g, fixed_formula=no_interaction_model.fixed_formula, by_subj_formula=no_interaction_model.by_subj_formula, by_item_formula="~ 1", ) constrained_models[g].fit(data_test)print(f"Fitting continuous model with {g} grammaticality levels...") unconstrained_models[g] = UnconstrainedClusteredMixedEffectsModel( n_grammaticality_levels=g, fixed_formula=no_interaction_model.fixed_formula, by_subj_formula=no_interaction_model.by_subj_formula, by_item_formula="~ 1", ) unconstrained_models[g].fit(data_test)
Model comparison
Finally, we will compute the model comparison using PSIS-LOO. These models are ranked by ELPD\(_\text{loo}\).
compare_dict = {"No interaction model": no_interaction_model.model_fit,"Minimal interaction model": twoway_interaction_model.model_fit,"Maximal interaction model": full_interaction_model.model_fit}for n_grammaticality_levels, m in constrained_models.items(): name =f"Constrained model ({n_grammaticality_levels} levels)" compare_dict[name] = m.model_fitfor n_grammaticality_levels, m in unconstrained_models.items(): name =f"Unconstrained model ({n_grammaticality_levels} levels)" compare_dict[name] = m.model_fitmodel_comparison = compare(compare_dict)model_comparison[["elpd_loo", "p_loo", "elpd_diff", "dse"]]
elpd_loo
p_loo
elpd_diff
dse
Constrained model (4 levels)
-10716.830739
566.988072
0.000000
0.000000
Unconstrained model (4 levels)
-10717.042327
567.278971
0.211588
0.629807
Constrained model (3 levels)
-10718.938079
569.969504
2.107341
0.684705
Unconstrained model (3 levels)
-10719.299001
569.839128
2.468262
0.880495
Constrained model (2 levels)
-10719.712935
567.872110
2.882196
1.703436
Minimal interaction model
-10721.546329
565.649372
4.715591
2.948452
Unconstrained model (2 levels)
-10721.878888
569.544818
5.048149
1.610423
Maximal interaction model
-10721.923465
574.947989
5.092726
1.902887
No interaction model
-10725.226354
573.342717
8.395615
4.284287
There are a few things to note about this comparison.
First, all models that have grammatical effects dominate the no interaction model. This ranking is not surprising, given the difference of differences we saw in the last section, but it is a good sanity check.
Second, the minimal and maximal interaction models have effectively the same ELPD\(_\text{loo}\), even though the \(p_\text{loo}\) for the maximal interaction model is nearly 10 points higher. This pattern indicates that the maximal interaction model fits better than the minimal interaction model–as we would expect–but when trading complexity off with fit, there is not reason to prefer the better-fitting maximal interaction model to the worse-fitting minimal interaction model (or vice versa).
Finally, nearly all the clustered mixed effects models dominate the minimal and maximal interaction models, with more levels (at least up to 4) improving the PSIS-LOO. This result, which is driven by improved fit without a substantial increase in complexity as evidenced by the \(p_\text{loo}\)s, is promising for the clustered mixed effects models. We need to be cautious in interpreting this ranking, however, since the ratio of difference in ELPD to dse–especially in for the minimal interaction model–is small and these comparisons are being conducted post hoc. Ideally, to confirm this ranking, we would collect a new sample that would likely need to be quite a bit larger than the one collected by Sprouse et al. (2016).
Digging into the clustered mixed effects models
One useful aspect of the clustered mixed effects models is that they allow us to dig into (i) the penalty along the acceptability continuum associated with ungrammaticality; and (ii) which level of grammaticality would be associated with a particular structure using the membership probabilities.
Grammaticality penalties
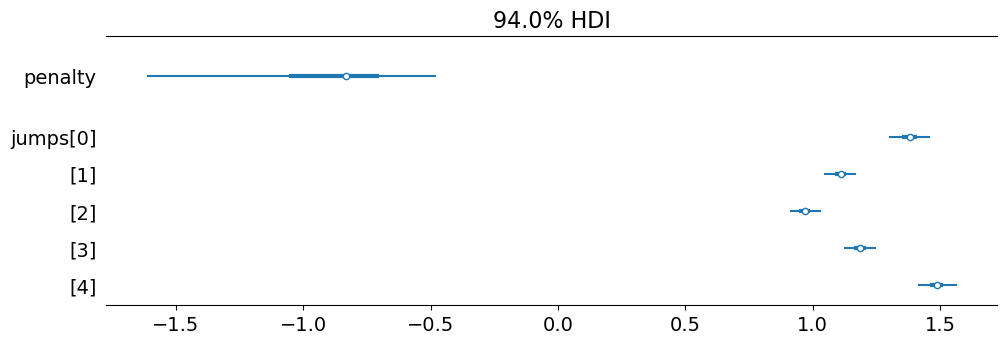
The penalty of each level of ungrammaticality in the constrained model is approximately -0.75.
For comparison, the effects of distance=long and structure=island are each about -1.5. So the effect of one increment of ungrammaticality is about half that of the effects of distance=long and structure=island.
import refrom arviz import summarydef format_factor_levels(x): extracted = re.findall("C\(([A-z]+).+?\)\[T\.([A-z]+)\]", x)return' x '.join([f"{k}={v}"for k, v in extracted])constrained_coefs = summary(constrained_models[4].model_fit, "fixed_coefs")constrained_coefs.index = constrained_models[4].fixed_predictors.columns.map(format_factor_levels)constrained_coefs[["mean", "sd", "hdi_3%", "hdi_97%"]]
mean
sd
hdi_3%
hdi_97%
6.935
0.365
6.270
7.634
distance=long
-1.606
0.426
-2.359
-0.784
structure=island
-1.407
0.437
-2.210
-0.588
island=SUB
-2.188
0.466
-3.091
-1.328
island=ADJ
-1.783
0.446
-2.629
-0.973
island=NP
-0.181
0.468
-0.981
0.740
dependency=RC
-3.002
0.467
-3.894
-2.119
dependency=DlinkedWH
-0.993
0.328
-1.606
-0.372
dependency=DlinkedRC
-2.717
0.475
-3.651
-1.881
distance=long x island=SUB
2.820
0.559
1.720
3.854
distance=long x island=ADJ
-0.187
0.547
-1.220
0.797
distance=long x island=NP
-1.260
0.552
-2.299
-0.205
structure=island x island=SUB
-2.169
0.577
-3.270
-1.126
structure=island x island=ADJ
-0.491
0.558
-1.649
0.480
structure=island x island=NP
0.869
0.574
-0.182
1.969
distance=long x dependency=RC
0.648
0.560
-0.444
1.675
distance=long x dependency=DlinkedWH
1.217
0.386
0.546
1.975
distance=long x dependency=DlinkedRC
0.424
0.560
-0.621
1.493
structure=island x dependency=RC
0.672
0.573
-0.428
1.721
structure=island x dependency=DlinkedWH
0.551
0.385
-0.173
1.250
structure=island x dependency=DlinkedRC
0.374
0.573
-0.631
1.539
island=SUB x dependency=RC
2.011
0.666
0.759
3.279
island=ADJ x dependency=RC
2.763
0.651
1.543
3.957
island=NP x dependency=RC
1.326
0.636
0.165
2.556
island=SUB x dependency=DlinkedWH
1.839
0.410
1.087
2.612
island=ADJ x dependency=DlinkedWH
0.406
0.402
-0.319
1.164
island=NP x dependency=DlinkedWH
-0.253
0.435
-1.049
0.580
island=SUB x dependency=DlinkedRC
2.783
0.646
1.585
4.035
island=ADJ x dependency=DlinkedRC
2.111
0.636
0.906
3.276
island=NP x dependency=DlinkedRC
1.367
0.640
0.194
2.547
distance=long x island=SUB x dependency=RC
-1.074
0.746
-2.465
0.341
distance=long x island=ADJ x dependency=RC
-0.675
0.805
-2.237
0.779
distance=long x island=NP x dependency=RC
-0.282
0.758
-1.678
1.156
distance=long x island=SUB x dependency=DlinkedWH
-1.749
0.496
-2.721
-0.874
distance=long x island=ADJ x dependency=DlinkedWH
-0.086
0.477
-0.987
0.783
distance=long x island=NP x dependency=DlinkedWH
-0.379
0.514
-1.366
0.538
distance=long x island=SUB x dependency=DlinkedRC
-0.915
0.761
-2.315
0.527
distance=long x island=ADJ x dependency=DlinkedRC
-0.359
0.787
-1.768
1.169
distance=long x island=NP x dependency=DlinkedRC
-0.322
0.763
-1.797
1.046
structure=island x island=SUB x dependency=RC
0.655
0.789
-0.944
2.056
structure=island x island=ADJ x dependency=RC
-0.620
0.831
-2.219
0.890
structure=island x island=NP x dependency=RC
-0.066
0.777
-1.468
1.426
structure=island x island=SUB x dependency=DlinkedWH
-0.798
0.497
-1.715
0.120
structure=island x island=ADJ x dependency=DlinkedWH
-0.290
0.477
-1.161
0.603
structure=island x island=NP x dependency=DlinkedWH
-0.245
0.522
-1.294
0.648
structure=island x island=SUB x dependency=DlinkedRC
-0.218
0.801
-1.740
1.292
structure=island x island=ADJ x dependency=DlinkedRC
-0.223
0.798
-1.664
1.271
structure=island x island=NP x dependency=DlinkedRC
0.150
0.780
-1.381
1.545
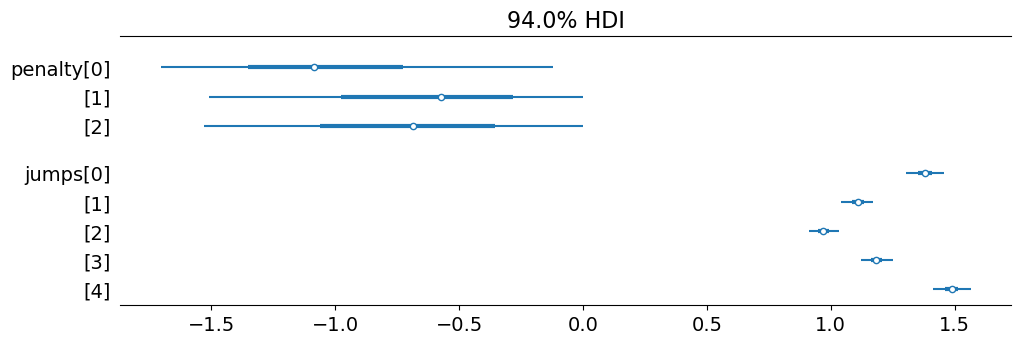
In contrast, the penalty for the first level of ungrammaticality in the unconstrained model is a bit over -1 with the remaining penalties being a bit stronger than -0.5.
And the pattern of fixed effects coefficients for the unconstrained model is very similr to that for the constrained model.
def format_factor_levels(x): extracted = re.findall("C\(([A-z]+).+?\)\[T\.([A-z]+)\]", x)return' x '.join([f"{k}={v}"for k, v in extracted])unconstrained_coefs = summary(unconstrained_models[4].model_fit, "fixed_coefs")unconstrained_coefs.index = unconstrained_models[4].fixed_predictors.columns.map(format_factor_levels)unconstrained_coefs[["mean", "sd", "hdi_3%", "hdi_97%"]]
mean
sd
hdi_3%
hdi_97%
7.024
0.467
6.161
7.821
distance=long
-1.613
0.421
-2.376
-0.795
structure=island
-1.446
0.429
-2.211
-0.576
island=SUB
-2.188
0.466
-3.069
-1.322
island=ADJ
-1.792
0.457
-2.624
-0.912
island=NP
-0.164
0.459
-1.063
0.682
dependency=RC
-3.018
0.456
-3.845
-2.166
dependency=DlinkedWH
-1.029
0.335
-1.640
-0.382
dependency=DlinkedRC
-2.744
0.461
-3.607
-1.865
distance=long x island=SUB
2.818
0.551
1.709
3.776
distance=long x island=ADJ
-0.186
0.544
-1.238
0.800
distance=long x island=NP
-1.310
0.546
-2.324
-0.258
structure=island x island=SUB
-2.146
0.574
-3.236
-1.074
structure=island x island=ADJ
-0.450
0.566
-1.523
0.590
structure=island x island=NP
0.866
0.549
-0.158
1.899
distance=long x dependency=RC
0.670
0.543
-0.328
1.694
distance=long x dependency=DlinkedWH
1.249
0.411
0.526
2.027
distance=long x dependency=DlinkedRC
0.460
0.543
-0.544
1.486
structure=island x dependency=RC
0.734
0.569
-0.305
1.812
structure=island x dependency=DlinkedWH
0.599
0.407
-0.183
1.305
structure=island x dependency=DlinkedRC
0.451
0.571
-0.649
1.479
island=SUB x dependency=RC
2.021
0.664
0.791
3.249
island=ADJ x dependency=RC
2.736
0.650
1.471
3.861
island=NP x dependency=RC
1.288
0.622
0.195
2.556
island=SUB x dependency=DlinkedWH
1.876
0.418
1.064
2.609
island=ADJ x dependency=DlinkedWH
0.443
0.409
-0.307
1.240
island=NP x dependency=DlinkedWH
-0.246
0.441
-1.081
0.590
island=SUB x dependency=DlinkedRC
2.784
0.631
1.517
3.905
island=ADJ x dependency=DlinkedRC
2.101
0.628
0.942
3.262
island=NP x dependency=DlinkedRC
1.337
0.626
0.088
2.466
distance=long x island=SUB x dependency=RC
-1.093
0.739
-2.407
0.398
distance=long x island=ADJ x dependency=RC
-0.645
0.780
-2.064
0.841
distance=long x island=NP x dependency=RC
-0.240
0.731
-1.579
1.168
distance=long x island=SUB x dependency=DlinkedWH
-1.784
0.504
-2.669
-0.782
distance=long x island=ADJ x dependency=DlinkedWH
-0.122
0.499
-1.034
0.803
distance=long x island=NP x dependency=DlinkedWH
-0.360
0.539
-1.402
0.588
distance=long x island=SUB x dependency=DlinkedRC
-0.915
0.750
-2.318
0.511
distance=long x island=ADJ x dependency=DlinkedRC
-0.356
0.758
-1.790
1.014
distance=long x island=NP x dependency=DlinkedRC
-0.287
0.736
-1.637
1.144
structure=island x island=SUB x dependency=RC
0.601
0.787
-0.846
2.085
structure=island x island=ADJ x dependency=RC
-0.652
0.835
-2.218
0.838
structure=island x island=NP x dependency=RC
-0.064
0.755
-1.475
1.384
structure=island x island=SUB x dependency=DlinkedWH
-0.850
0.514
-1.794
0.112
structure=island x island=ADJ x dependency=DlinkedWH
-0.338
0.505
-1.272
0.605
structure=island x island=NP x dependency=DlinkedWH
-0.241
0.543
-1.243
0.752
structure=island x island=SUB x dependency=DlinkedRC
-0.268
0.798
-1.746
1.285
structure=island x island=ADJ x dependency=DlinkedRC
-0.280
0.799
-1.807
1.158
structure=island x island=NP x dependency=DlinkedRC
0.137
0.752
-1.256
1.592
Membership probabilities
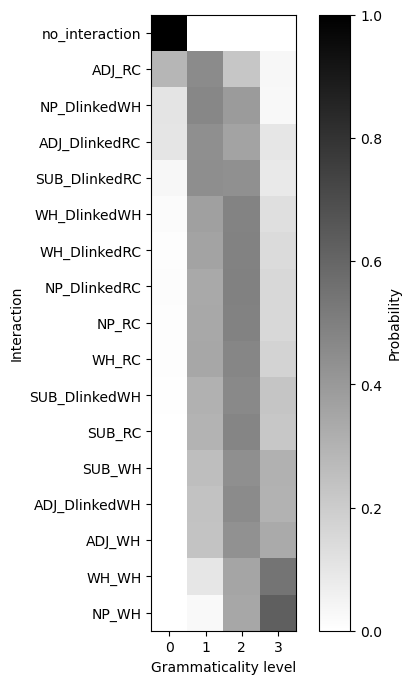
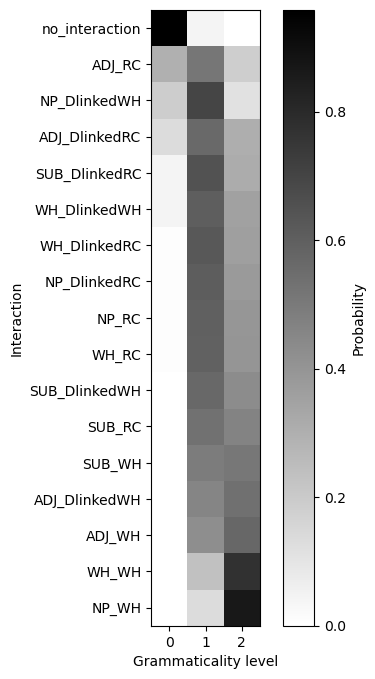
Turning to the level of grammaticality associated with particular structures, in the constrained model, we see that the majority split between levels 1 and 2, with level 3 reserved for WH question formation out of an NP or WH island.
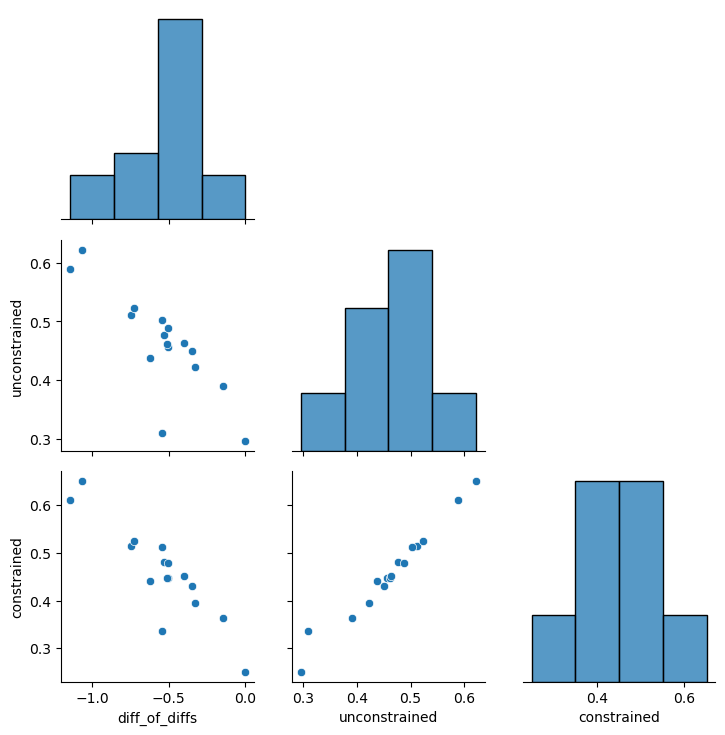
Comparing the expected grammaticality level for each structure with the difference of differences we observed for that structure, we see a very tight correlation.
In this first module of the course, we focused on minimally extending standard statistical models used in analyzing acceptability judgments–generalized linearmixed effects models–in order to probe the nature of the grammatical representations that drive acceptability judgments. We considered two possibilities discussed by Sprouse (2018): (a) that the grammatical representations underlying acceptability judgments are discrete (or categorical); and (b) the grammatical representations are continuous (or gradient).
The basic recipe, which we will repeat through the course, was (i) to define two or more (families of) models–in this case, our not interaction, minimal interaction, maximal interaction, and clustered interaction models; (ii) to fit both models to the data from some acceptability judgment data–in this case, to the data collected by Sprouse et al. (2016); and (iii) to compare how well the two models fit the data, weighed against some measure of how parsimonious (or conversely, complex) each model is using PSIS-LOO.
We saw that the models that inject additional discrete structure into the standard mixed effects models not only imrpove fit while keeping complexity at bay, they are also quite interpretable. In the next module, we will look at a similar approach to modeling inference judgment data.
References
Gelman, Andrew, Jessica Hwang, and Aki Vehtari. 2014. “Understanding Predictive Information Criteria for Bayesian Models.”Statistics and Computing 24 (6): 997–1016. https://doi.org/10.1007/s11222-013-9416-2.
Sprouse, Jon. 2018. “Acceptability Judgments and Grammaticality, Prospects and Challenges.” In The Impact of the Chomskyan Revolution in Linguistics, edited by Norbert Hornstein, Howard Lasnik, Pritty Patel-Grosz, and Charles Yang, 195–224. Berlin, Boston: De Gruyter Mouton. https://doi.org/doi:10.1515/9781501506925-199.
Sprouse, Jon, Ivano Caponigro, Ciro Greco, and Carlo Cecchetto. 2016. “Experimental Syntax and the Variation of Island Effects in English and Italian.”Natural Language & Linguistic Theory 34: 307–44. https://doi.org/10.1007/s11049-015-9286-8.
Vehtari, Aki, Andrew Gelman, and Jonah Gabry. 2017. “Practical Bayesian Model Evaluation Using Leave-One-Out Cross-Validation and WAIC.”Statistics and Computing 27 (5): 1413–32. https://doi.org/10.1007/s11222-016-9696-4.
Footnotes
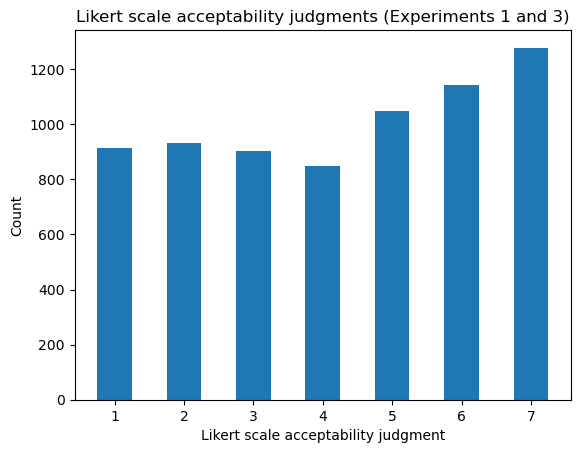
Note that this distribution is different from the one observed here because we are only fitting to the test items. The fillers are removed.↩︎
A good analogy here is between an unpaired \(t\)-test and a paired \(t\)-test.↩︎